ETL vs ELT: What's the difference?

Last edited on Apr 16, 2026
The battle between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) is one of the most important conversations in modern data management. As data continues to expand in volume and complexity, organizations must decide which approach is best suited to their analytics needs.
When comparing ETL vs ELT, the key difference lies in when and where the data transformation occurs. With ETL, data is transformed before loading, while in ELT, data is transformed after loading into the data warehouse.
In this article, we will explore ETL vs ELT, breaking down their differences, processes, and strengths to help you decide which is best for your data strategy.
What is ETL?
ETL stands for Extract, Transform, Load. This method prepares data for analysis by extracting it from various sources, transforming it into a structured format, and loading it into a target system.
In ETL workflows, most meaningful data transformation occurs outside this primary pipeline in a downstream business intelligence (BI) platform.
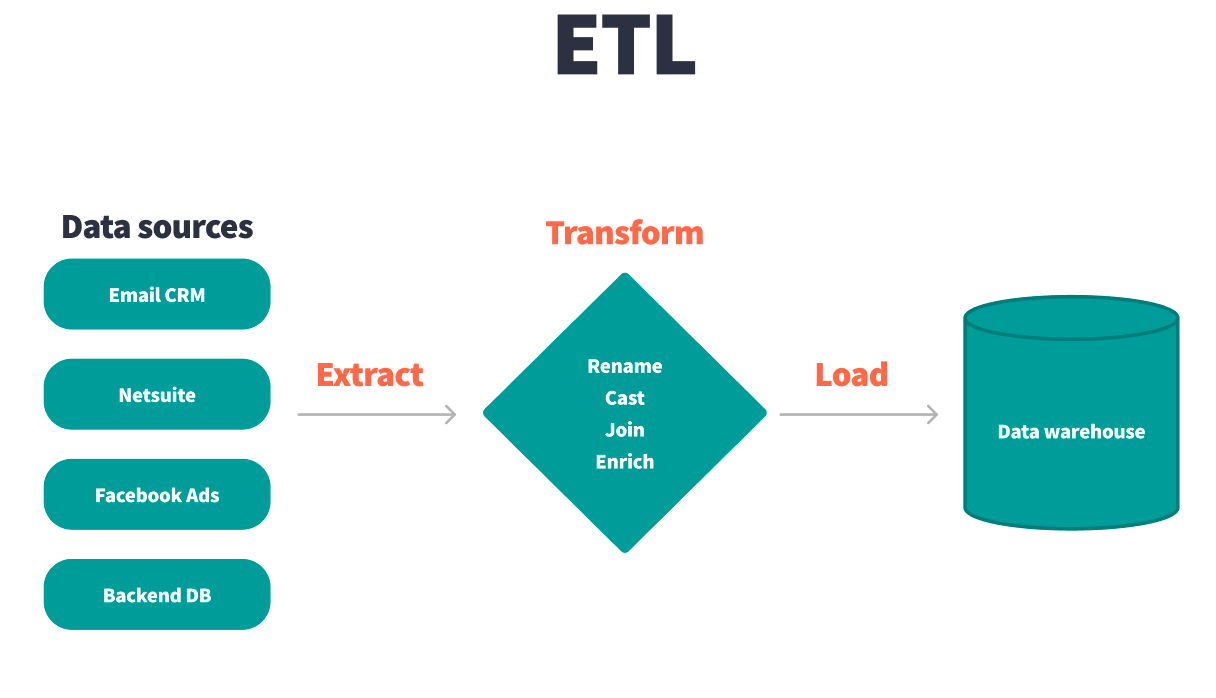
The ETL process
- Extract: Data is pulled from various sources, often in unstructured or semi-structured formats.
- Transform: The data undergoes a transformation process, cleaning, formatting, and structuring it for analysis.
- Load: Once transformed, the data is loaded into a target system, typically a data warehouse, where it becomes available for querying and reporting.
What is ELT?
ELT stands for Extract, Load, Transform and has gained popularity in cloud-native environments. In this approach, data is extracted and loaded into a data warehouse first, allowing the data to be transformed using the warehouse’s computing power.
ELT has emerged as a paradigm for how to manage information flows in a modern data warehouse. This represents a fundamental shift from how data previously was handled when ETL was the data workflow most companies implemented.
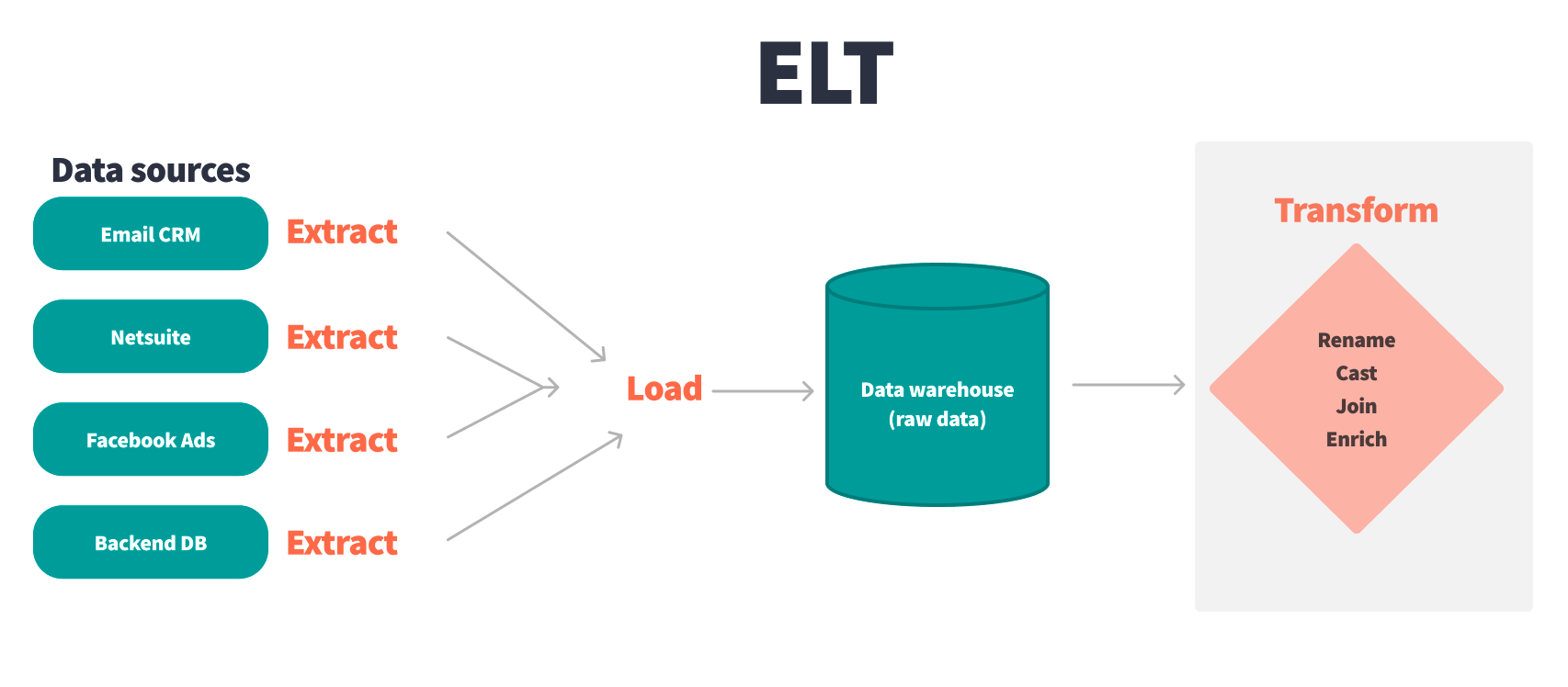
The ELT process
- Extract: Data is collected from various sources, just as in ETL.
- Load: The raw data is loaded into a data warehouse without any transformations.
- Transform: After the data is stored, transformations are performed within the warehouse, leveraging its computational power.
ETL vs ELT: a side-by-side comparison
While both ETL and ELT are designed to move data from one place to another, they differ in how and when data transformations occur:
- Order of operations:
- ETL transforms data before loading it into the warehouse.
- ELT loads data first and then transforms it inside the warehouse.
- System requirements:
- ETL typically uses external tools to transform data before reaching the warehouse.
- ELT relies on the power of modern data warehouses to handle transformations, reducing the need for complex pre-processing.
- Efficiency:
- ETL can be slower for large datasets, as the transformation happens before data is loaded into the warehouse.
- ELT can speed up the process, particularly in cloud-based environments, by loading raw data quickly and transforming it later.
- Use cases:
- ETL is often used in highly structured environments that require stringent data governance.
- ELT is best suited for environments with high volumes of unstructured data, where transformation can occur after the data is already in the warehouse.
Transitioning from ETL to ELT means that you no longer have to capture your transformations during the initial loading of the data into your data warehouse. Rather, you are able to load all of your data, then build transformations on top of it.
Making the case for ELT in the ETL vs ELT debate
ELT aligns with the scalability and flexibility of modern data stacks, enabling organizations to work with large datasets more efficiently. While there are many benefits to using ELT over ETL, below are the primary benefits.
Leverage cloud infrastructure
ELT takes advantage of the massive processing power of cloud-native data warehouses like Snowflake, BigQuery, and Redshift. By loading raw data into the warehouse first, ELT enables these systems to handle transformations at scale, which is particularly valuable when working with large volumes of data.
Faster data availability
With ELT, raw data is loaded into the warehouse immediately, making it accessible for analysis more quickly. This reduces the delay often seen in ETL processes, where data must be transformed before it’s available for querying.
Cost efficiency
ELT reduces the need for expensive on-premises hardware or complex ETL tools. Instead, it capitalizes on the inherent processing capabilities of cloud data warehouses, optimizing both performance and cost. In modern data stacks, offloading transformation tasks to cloud services can lead to significant cost savings.
Flexible, iterative transformation
ELT allows for more flexible data transformations. Since the raw data is already in the warehouse, analysts and data engineers can transform data iteratively, applying changes and optimizations without having to reload or reprocess the entire dataset. This flexibility makes it easier to adapt to evolving business needs and ensures that teams can always work with the latest data.
Data democratization
By loading raw data into the warehouse first, ELT supports a more self-service data model. Analysts and data teams can access and transform data as needed without being bottlenecked by upstream ETL processes. This democratization fosters greater agility and collaboration across teams.
How dbt fits into the ELT workflow
dbt plays a crucial role in the ELT process by serving as the transformation layer within the data warehouse. While ELT relies on loading raw data into the warehouse, dbt empowers teams to manage and automate their transformations, ensuring the data is clean and analytics-ready.
dbt features include:
- Version-controlled transformations: dbt enables version control for all transformations, making it easy to track changes and collaborate across teams. This ensures data transformations are organized and consistent.
- Automation and scheduling: With dbt, you can automate transformation processes, ensuring that the most up-to-date data is always available for analysis. This fits perfectly within an ELT workflow, where transformation happens after the data is already in the warehouse.
- Comprehensive testing: dbt offers built-in testing capabilities to validate transformations, ensuring data quality and integrity throughout the ELT process.
At dbt Labs, we advocate for a strong focus on data transformations, especially in analytics-driven workflows where clean and structured data is crucial for making informed decisions.
Sign up for a free dbt account to start managing your data transformations more effectively and take control of your ETL journey today.
FAQs: ETL vs ELT
Get started in dbt
Join the analytics engineers building data infrastructure that actually scales.
Install dbt Wizard CLI
Get started with an agent purpose-built for analytics engineering. It knows which tool to call, which context to pull, and checks its own work before surfacing anything to you.



