Building a data quality framework with dbt and dbt Cloud

Mar 21, 2024
Product
We’ve all heard the saying: garbage in / garbage out. Applying that notion to the realm of data has never been more important. Not only are important strategic decisions being made from descriptive data, but as AI and machine learning continue to grow in importance for organizational decision making, the stakes are higher than ever to manage and optimize data quality.
Yet, data pipelines are notoriously hard to manage. Without a solid framework for testing and pipeline maintenance in place, data teams often find themselves with poor outcomes:
- They can’t ship fast enough without risking breaking changes, which means
- They lose the trust of the business teams that depend on data, and so organizations becomes less data-driven
Here are a few examples of how this might manifest:
- A data analyst updates a query running live in production, and introduces a bad join, which causes other downstream queries to break. (Not pointing fingers, either! I would venture to say most people working in data have been this data analyst at some point in their career.)
- The product team adjusts the order of questions in a questionnaire, which has the unintended consequence of reducing the response rate for questions that have been moved to the end. Meanwhile, executive leadership sees a sudden sharp decrease in a customer satisfaction KPI they use to track customer sentiment, and they sound the alarm to the data team. The data team spends a day tracing their web of SQL scripts back to the original source data to defend their own work.
The testing capabilities in dbt and dbt Cloud enable you to turn this situation on its head, and become proactive about data quality. With dbt Cloud:
- Instead of the data analyst updating a production query directly, they have a workflow to automatically test their changes in lower environments first, before it affects production.
- The data team can detect the decrease in the customer satisfaction KPI proactively. They can act on this knowledge by following up with the product team directly and alerting management, increasing trust by putting themselves in the driver’s seat working towards a resolution.
After all, what good is all this data if it takes too long for you to manage, and your downstream consumers can’t derive consistent and actionable answers from it?
How to approach testing in dbt
dbt and dbt Cloud offer various testing capabilities, but it can be difficult to know where to start. Below is our recommended framework for how to approach testing in dbt, in sequential order of relative ease of implementation and expected benefit. We’ll go into detail on each of these in this post.
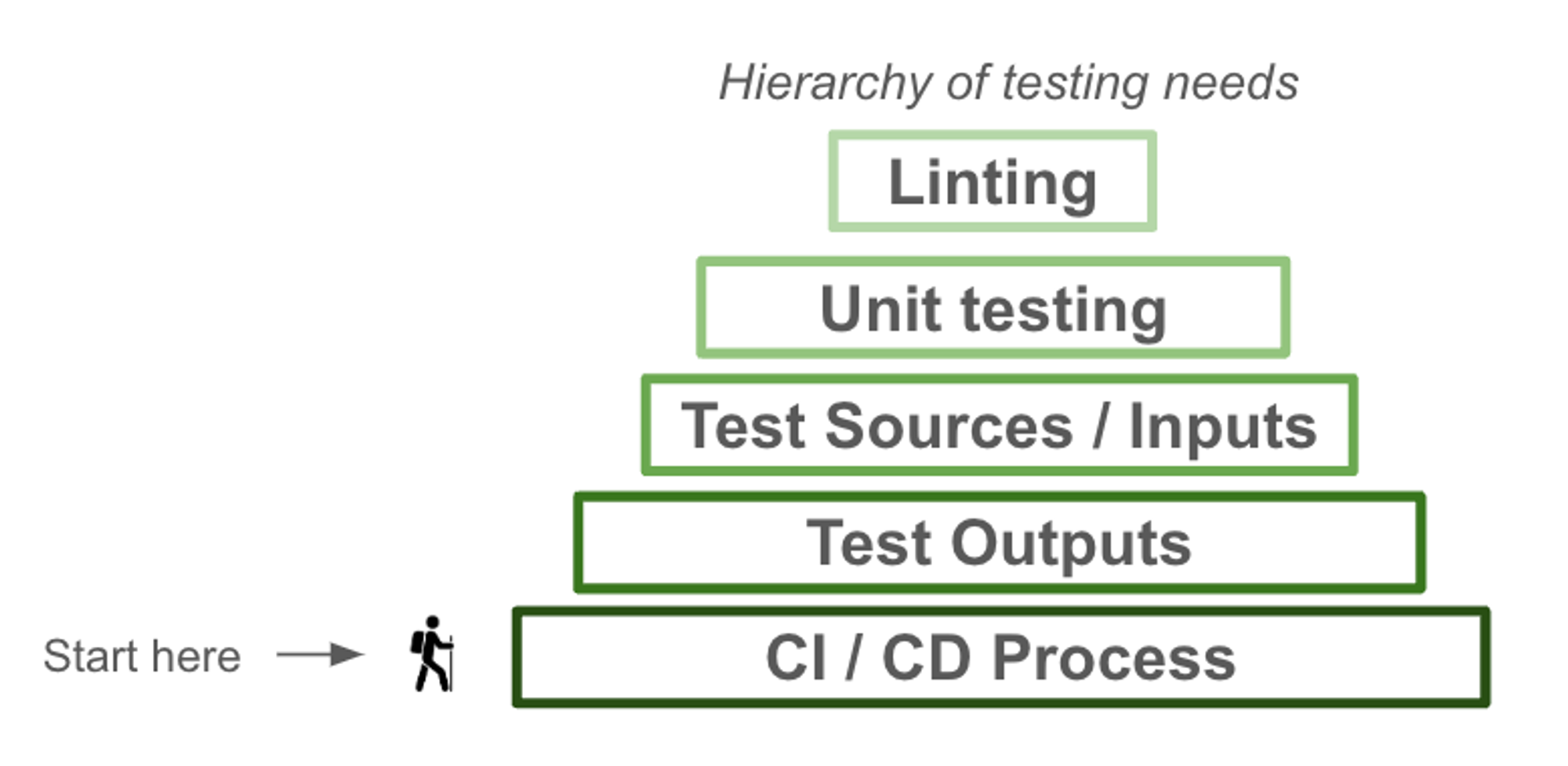
Depending on the processes you already have in place for data testing, your testing implementation may not follow this exact order. For example, if you already have robust data type checks and constraints in your data loading process, you might skip or deprioritize the third step of implementing source data testing.
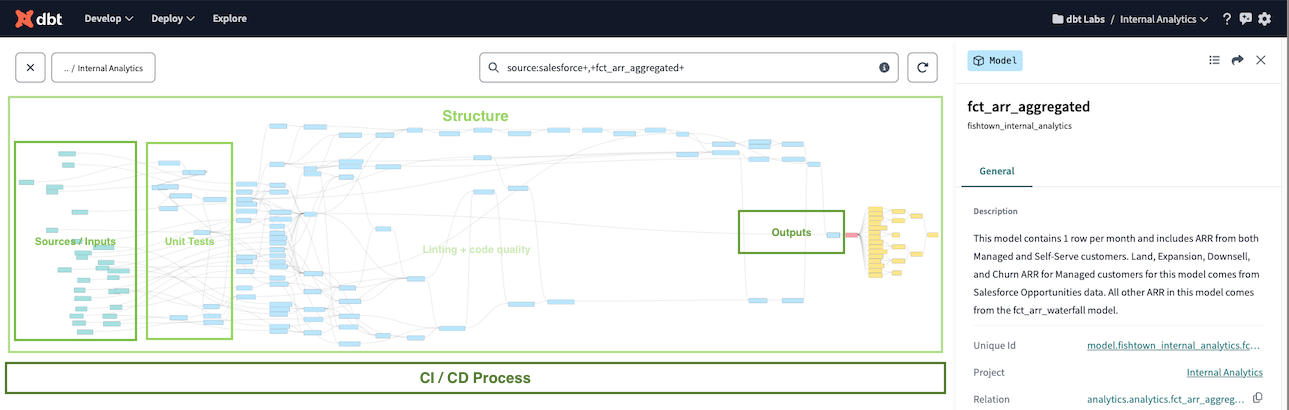
Here’s an example of how this testing framework is applied across dbt Labs’ Internal Project DAG, focused on revenue data:
Key concepts
If you need a refresher on dbt tests, keep reading! If not, you can jump straight into the various approaches in the next section.
What are dbt tests?
Generally speaking, tests are operations declared in the dbt codebase to audit the data in your data platform. The dbt ecosystem extends out-of-box dbt test logic with additional packages like the classic dbt expectations. There are many other packages out there that you can use to cut down on test development time.
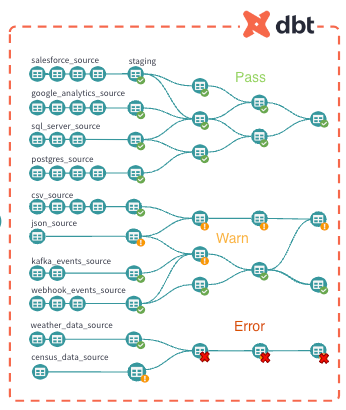
Below are a few examples of data tests, unit tests, or source freshness assertions you may make about your data:
- A certain column must not contain duplicate values
- During a migration, 99% of records from Table A and Table B must be exact matches
- Source data must have been loaded within the past 24 hours
- Verify a piece of code that formats some wonky timestamp data works correctly
For data tests, after each dataset in the dbt pipeline is built, dbt performs the audit, then determines whether it should move on to build the next dataset based on the test result (pass, fail, warn). If a check fails, you can configure dbt to simply raise a warning and still continue building downstream models, or you can dictate that the run should stop and throw an error.
Running dbt in separate environments
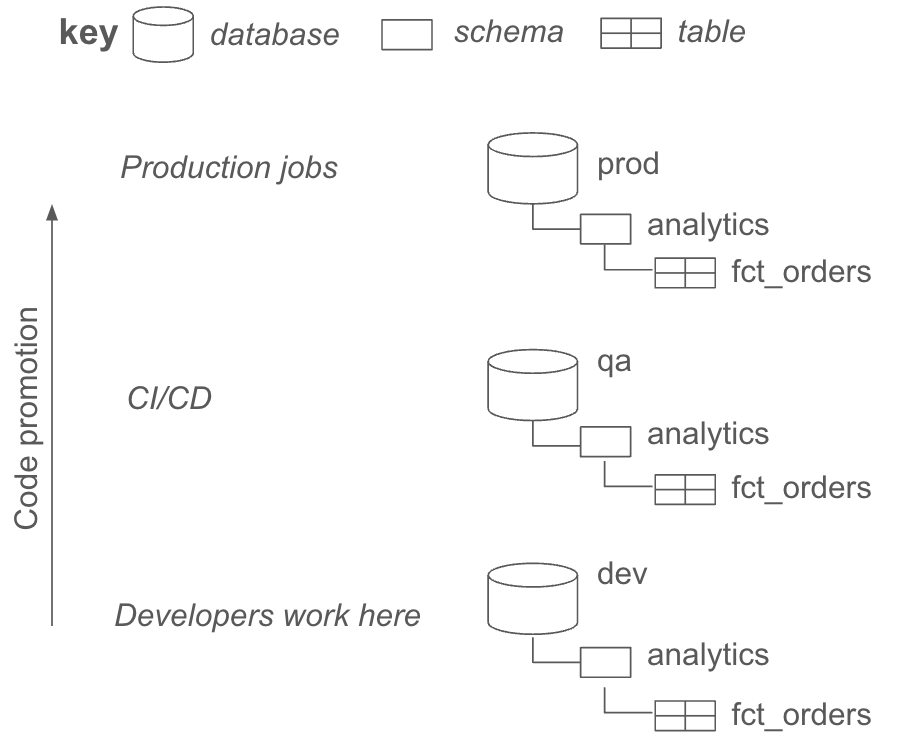
When thinking about running tests in this framework, it helps to be aware of dbt’s native capabilities for running data models and their tests in separate environments. dbt reasons about data environments by running your data models in distinct databases and schemas to represent dev, QA, and production. dbt is highly flexible in this manner: your team can choose whether dbt manages separate environments in distinct databases with the same schema, schemas within a database, etc.
For example, if I have a dbt model for a table called fct_orders, the database and schema structure might look like:
Building your testing infrastructure with dbt
Let’s jump into the various testing capabilities, how they work, and their benefits.
CI/CD
What it is
- Automated testing jobs supported by dbt Cloud, to prevent bad code from making it to production.
How it works
- When analytics engineers make changes to data pipelines, dbt Cloud CI runs ONLY those changes and any related downstream datasets in temporary testing schemas.
- This all happens in parallel, and builds for outdated commits are canceled automatically.
- When the CI process finds a failure, the analytics engineer resolves the issue before testing again.
Benefits
- Automating a “dry run” of your dbt project in a separate pre-production environment greatly reduces the risk of human error.
- Users can add branch protection rules to prevent a PR with a failed CI job from being able to be merged into production.
- Provides a repeatable process onto which additional quality assurance processes can be built.
Example
If your organization is implementing dbt, CI/CD is a critical component. Without it, you miss the opportunity to verify how new code actually works before it moves to production. You can build CI pipelines in dbt Cloud that run with maximum efficiency. Check out this guide to help you get started building your data platform with the power of CI / CD.
Where are models built in CI?
When running your pipelines in CI, dbt Cloud builds into temporary databases and schemas which don’t impact any datasets running in production. It does this by overriding the default and instead building into a schema with a unique name for the pull request that triggered the build.
Testing DAG outputs
What it is
- Applying dbt tests to the last models in the DAG. These are typically the models that power dashboards, data applications, ML models, etc.
How it works
- Proactively identifies when there is risk that downstream dependencies are broken.
Benefits
- You learn about problems before your stakeholders do.
- By tackling issues proactively, you reduce the number of firedrills you’re triaging (and get more sleep!)
Example
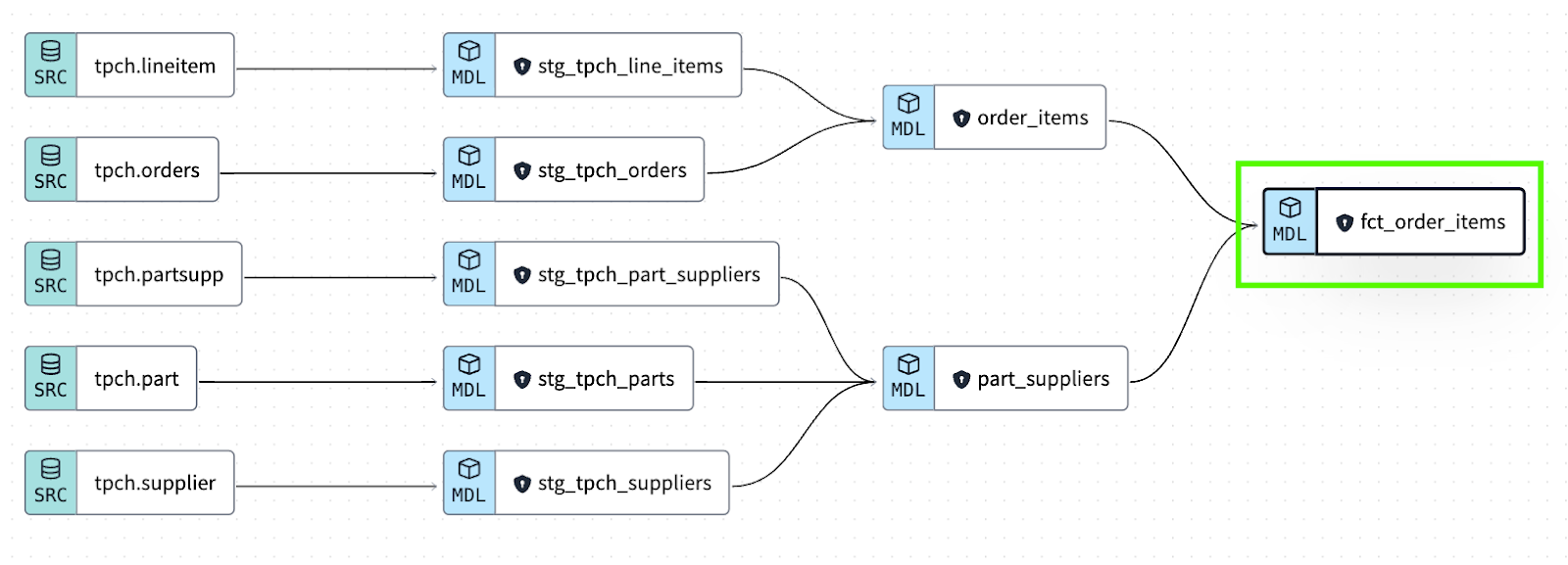
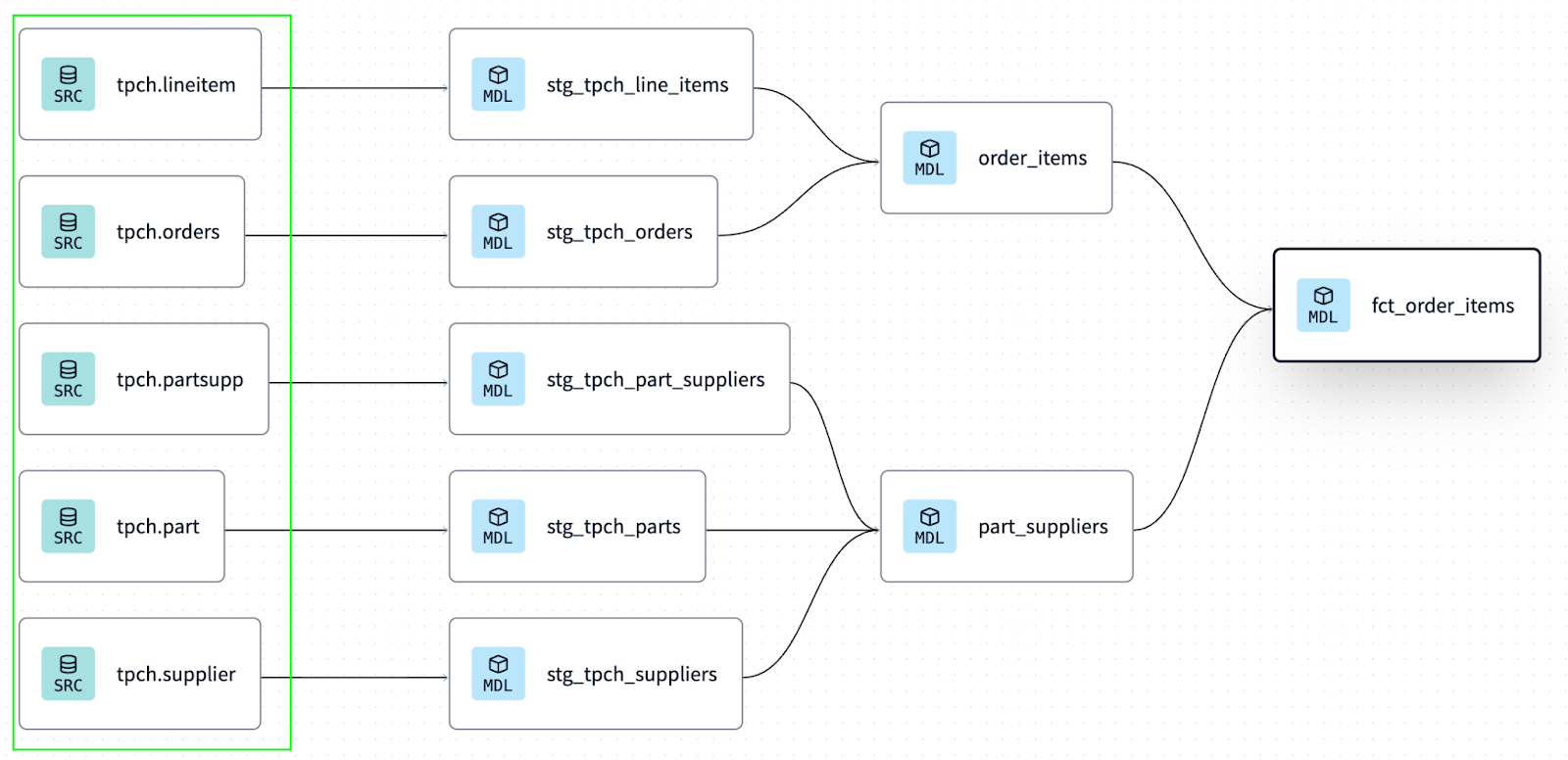
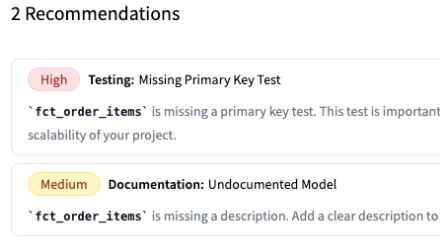
After your CI pipelines are in place, the next step is to ensure you have adequate testing on the data models dbt owns and other systems consume. These are the datasets that power things like the dbt Semantic Layer, BI dashboards, and ML models. For example, in this example DAG, I want to make sure the fct_order_items model is well-tested:
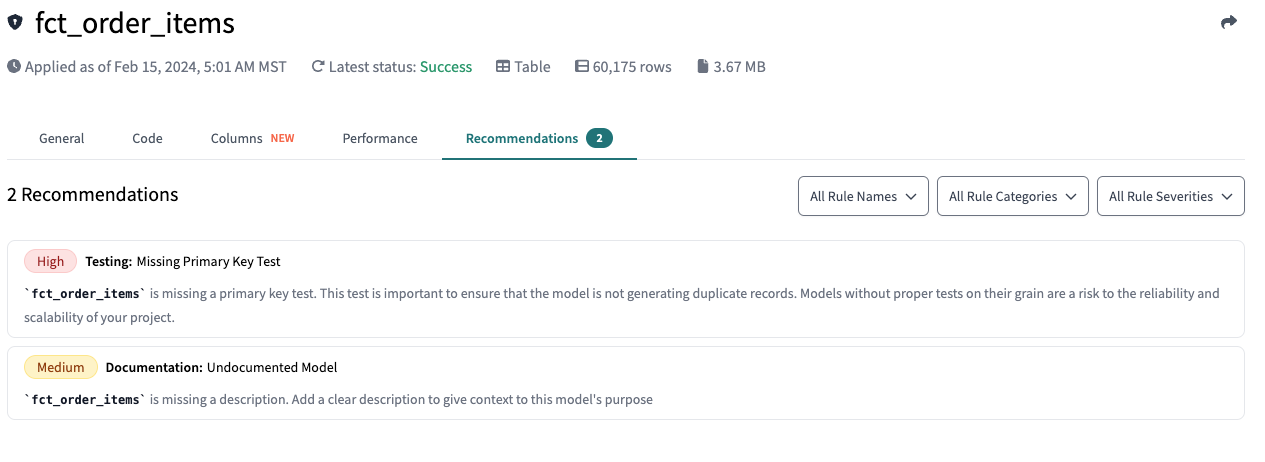
I have a few options: I can use dbt Explorer to get proactive recommendations on when a model isn’t up-to-par (with guidance on what to do next):
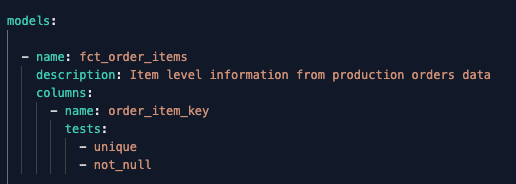
I can also add a test and description to this model by updating its configuration, as shown below:
These capabilities allow us to make sure data models have tests applied in key parts of the pipeline, and that they have documentation in place so consumers know how to interpret the data they contain.
Testing inputs
What it is
- Verifies that datasets at the beginning of the processing pipeline are correct.
- Source freshness verifies that the same “raw” datasets are up-to-date with fresh data for downstream processing.
How it works
- Identifies when new records are present in source datasets.
- Tests source data to identify any invalid records that should not be processed downstream.
Benefits
- Reduces data platform spend from running data transformations on already-processed data.
- Automatically identifies when new raw data is present, so pipelines can start running.
Example
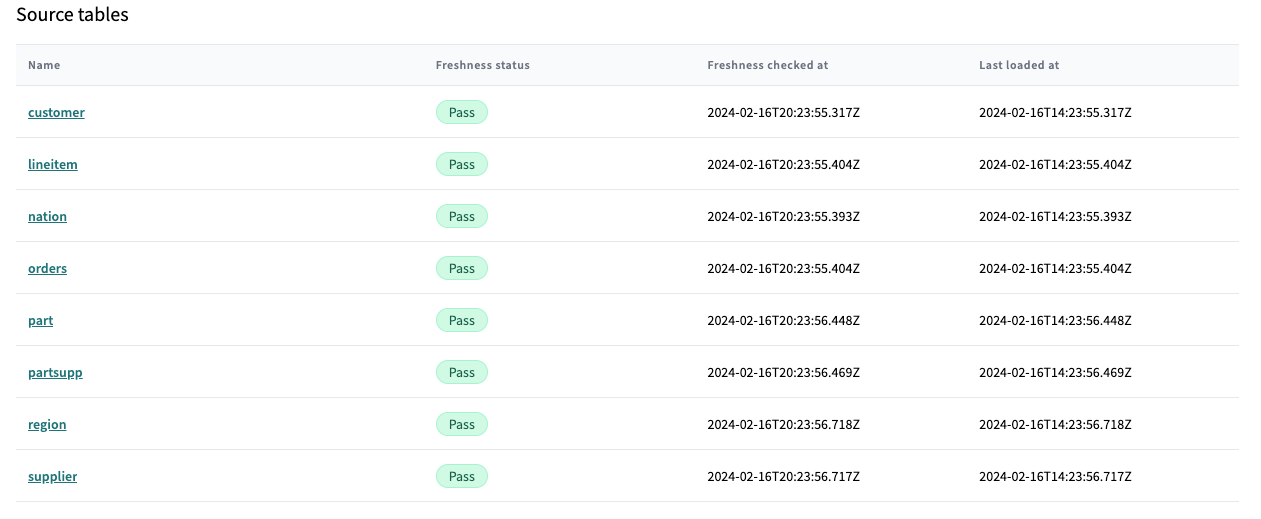
To manage data sources properly, the goal is to make sure they’re both up-to-date and conform to expectations. Going back to our example DAG, the source layer is farthest to the left:
Again, I have choices! I can use dbt Explorer source details to quickly understand the freshness of source data, and debug as needed.
I can also configure both freshness checks and tests on raw sources, as shown below:
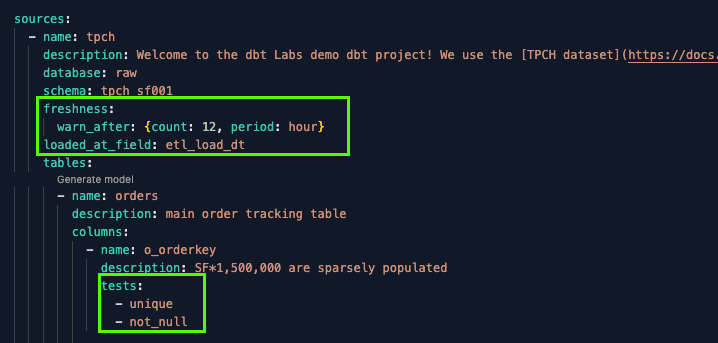
Assessing the structure of source data is key in guarding data pipelines against schema drift. Without this capability, data teams remain vulnerable to situations like the example described in the intro, where the product team implemented a breaking change unbeknownst to the rest of the organization. Freshness testing allows you to identify when source data is out-of-date, alert on it, and avoid reprocessing the same records downstream.
Unit testing
Now available in dbt Cloud! (And coming to dbt Core with the v1.8 release!) This is a long-requested dbt feature, which we’re thrilled to support. We’re grateful to the many dbt community members who’ve contributed to this capability.
What it is
- Uses static input and expected output datasets to verify dbt models perform expected transformations.
How it works
- Create mock input and output records in .ymls or .csv files.
- Enables testing dbt code at the column-level, without needing to specify ALL columns of an input table.
Benefits
- Reduces costs because SQL logic is validated before the entire model is materialized.
- Proves that a change implemented by a developer (rather than the underlying data) is the root of a problem.
Example
Unit tests are best applied on the models which you’ve found through experience to be most problematic. They’re a tool suited for making absolutely sure your business logic is correct, before it’s pushed to your data platform. This is most common in situations where there can be many edge cases like regexes or complex case statements.
Let’s say you need to deal with some raw orders data with poorly and inconsistently formatted dates from multiple upstream systems. Your dbt SQL might look like:

You can apply a unit test to the model like this:
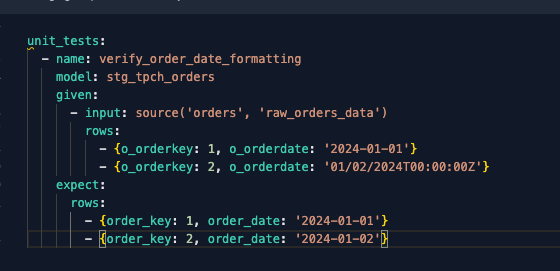
This will ensure that the sequence of replacements and date casting in the query actually translates the value ‘01/02/2024T00:00:00Z’ to the simple YYYY-MM-DD date format you want. As your sources evolve and you need to catch additional edge cases, it’s simple to add them to the input rows of your unit test without additional overhead.
As a best practice, we recommend to run unit tests in development and CI environments—and to exclude them in production, as static inputs won’t change.
Linting
What it is
- Determines whether code is formatted according to organizational standards.
How it works
- Using tools like SQLFluff, organizations define rules (e.g. SQL statements must use trailing commas). When developers write code that violates such rules, they are flagged and must be fixed before being able to commit their code.
- The dbt Cloud IDE supports linting with SQLFluff natively.
Benefits
- Keeps the codebase readable and standardized.
- Readability promotes faster development.
Example
dbt Cloud natively supports both SQLFluff and sqlfmt in the Cloud IDE. These tools provide an opinion about how code should actually be written and formatted. For SQLFluff, you can stick with the default rules implemented by dbt Cloud, or you can bring your own config file to apply custom rulesets to dbt pipelines.
Measuring Your Progress
dbt Explorer is a fantastic resource for benchmarking the structure of your dbt project(s). It provides intuitive visualizations based on metadata from every dbt run to summarize the structure of what you’ve built in an auditable way. You can use the lineage graph and contextual data in dbt Explorer to:
- Verify that all your source data have freshness checks configured, and flag the ones that don’t.
- Check that all the ending models of the DAG have tests configured.
- Assert rules about the structure of the models and how they connect. And, dbt Cloud provides a number of out-of-box checks to do just that!
You can also leverage the dbt project evaluator to enforce these best practices.
Example custom evaluation
You can also build on top of the project evaluator in combination with dbt Cloud CI/CD to automatically check that developers are following custom rules for your organization. Say for example, you wanted to make sure your developers don’t add duplicate source mappings. There can be many raw data sources in a dbt project (at enterprise scale, thousands are not uncommon). It can be easy for development teams who want to move fast to create a new mapping, pointing to the same underlying raw data.
This redundancy makes it harder to make sure there are good checks on source freshness, and creates the potential for the dbt DAG lineage to show unnecessary information. Downstream dbt models will still run, but in this situation the fidelity of the project documentation is lower.
Here we show an example custom test to confirm there are no duplicate source declarations in the project.
-- in tests/test_duplicate_sources_exist.sql
select *
from -- this model exists in the project evaluator packageIf the test finds any records of sources that point to the same raw table in your cloud data platform, but have separate dbt mappings, they’ll be flagged. Going a step further, you can set up the commands in your dbt Cloud CI / CD jobs to run this custom check each time an analytics engineer creates a pull request.

And with this setup in place, you don’t need to worry about duplicate source mappings!
Methodically improve your test coverage with dbt Cloud
The robust set of tools in the dbt ecosystem give you many options for becoming more proactive about shipping trusted data faster. With so many approaches available, it’s useful to consider how to sequence testing implementation. The test framework we provided (CI/CD pipeline, test outputs, test sources, unit test, lint) gives users a scalable approach to prioritization. Perhaps implicit in all of this, is the value derived from applying data testing best practices in the same tooling used to run transformation logic itself. The simplicity and power of using a single tool makes it much easier to ensure that tests are consistently applied to the right datasets.
If these robust testing capabilities are getting you curious about upgrading to dbt Cloud, here’s a helpful step-by-step guide on how to get started migrating from dbt Core to dbt Cloud.
For all these reasons, we think this information will help analytics engineers sleep better at night, knowing they manage trusted data.
To learn more about dbt Cloud, check out our whitepaper or schedule a demo.
Last modified on: Feb 21, 2025
Early Bird pricing is live for Coalesce 2025
Save $1,100 when you register early for the ultimate data event of the year. Coalesce 2025 brings together thousands of data practitioners to connect, learn, and grow—don’t miss your chance to join them.
Set your organization up for success. Read the business case guide to accelerate time to value with dbt Cloud.